Today as we take our walk with Cassandra, we will be visiting her three C’s, composites, counters, and collections!
Our tweets column family from last post has a single row per user, with composite columns sorted by a first component timestamp. This design showcases a common and effective data arrangement with Cassandra (C*) – time indexed logs. Grouping elements in wide rows by time is excellent for retrieving items by time range, but our approach will overflow if a user posts more tweets than a single row can hold (two billion). One solution is to rollover to new rows on a coarse time value (e.g. months) and use columns for posts between months. With CQL:
DROP TABLE tweets;CREATE TABLE tweets ( email varchar, month_posted timestamp, time_posted timestamp, subject varchar, tweet varchar, PRIMARY KEY ((email, month_posted), time_posted) );Exit cqlsh with quit; then add sample data from this file with cqlsh --file <file>. From cassandra-cli, list tweets;
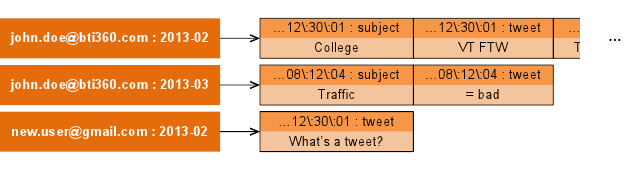
Now we have composite row keys of user and month_posted, where each row contains tweets posted in that month. Two billion tweets in a month would be a tall order, so this is likely safe from overflow. It’s not a perfect solution – users who post infrequently would have tweets dispersed across many rows – but it serves our purposes for today.
Next, we have counter columns, which allow increments and decrements from a fixed value. Counters require a column family consisting of only counter columns. Consider these queries:
- How many followers does a user have?
- How many users follow a particular user?
- How many tweets has a user posted?
Counters require a column family containing only counter columns, so queries like those above are often grouped into a single column family. Create a user_metadata column family with cqlsh:
CREATE TABLE user_metadata ( email varchar, followers counter,following counter, tweets counter, PRIMARY KEY (email) );UPDATE user_metadata SET followers = followers + 1, following = following + 2, tweets = tweets + 3 WHERE email = ‘john.doe@bti360.com’;SELECT * FROM user_metadata WHERE email = ‘john.doe@bti360.com’;
Notice UPDATE, not INSERT, was used to add metadata for a user. Counters assume an initial value of 0, and can only be incremented or decremented, never set to specific values. Next, consider queries for:
- Who follows a certain user?
- Who is a certain user following?
One can have column families for these, but collections (sets, lists, maps) offer an alternative:
ALTER TABLE users ADD followers set<text>;UPDATE users SET followers = {'new.user@gmail.com'}
WHERE email = 'john.doe@bti360.com';ALTER TABLE users ADD following set<text>;UPDATE users SET following = {'new.user@gmail.com'}
WHERE email = 'john.doe@bti360.com';UPDATE users SET following = following + {'bob@yahoo.com'}
WHERE email = 'john.doe@bti360.com';SELECT followers, following FROM users WHERE email = ‘john.doe@bti360.com’
We leverage sets in the users column family to service both of these queries, which ensure that no duplicate users exist in followers or following. Further, the last UPDATE demonstrates the sets can be updated as new elements arrive without mangling existing entries.
Congratulations! You’ve now been introduced to basic and intermediate data modeling with C*. Tune in next time where we shift our attention to exploring the high availability and fault tolerance Cassandra offers!