As we mentioned in our previous post, today we’ll be going behind the scenes with Cassandra and diving deeper into her data modeling. Cassandra Query Language Shell (cqlsh), a recent addition, has made data modeling with Cassandra (C*) much easier. It also obscures the true data organization, as we mentioned in our previous post. From a terminal, launch cassandra-cli, cqlsh’s predecessor. From the [default@unknown] prompt, USE demo; to enter our keyspace and list users; to show all rows in the users table. Among others, this entry should appear:
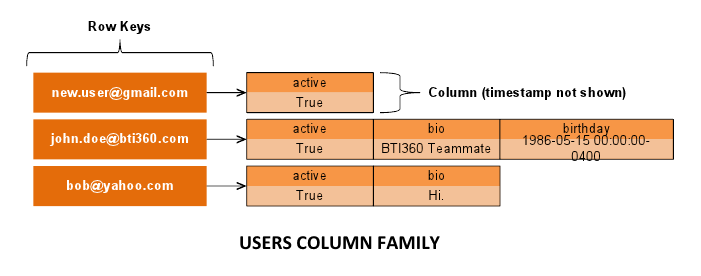
RowKey: new.user@gmail.com
=> (column=, value=, timestamp=1360436953050000)
=> (column=active, value=01, timestamp=1360436953050000)Our email primary key is a “row key”, containing columns sorted by name. Ignoring the empty column, the “new.user@gmail.com” row contains a single column for the active field. The nulls cqlsh showed for bio and birthday don’t exist. Columns are 3-tuples of a name, value, and a timestamp, which is automatically set by C* when a field is updated. This sparse data structure, termed a Column Family, is the cornerstone of data modeling in C*.
CREATE TABLE users (
email varchar,
bio varchar,
birthday timestamp,
active boolean,
PRIMARY KEY (email)
);Let’s take a look at the tweets column family next. In cassandra-cli enter assume tweets validator as UTF8; to force column values to be displayed as strings, then list tweets;
CREATE TABLE tweets(
email varchar,
time_posted
timestamp,
tweet varchar,
PRIMARY KEY (email,
time_posted)
);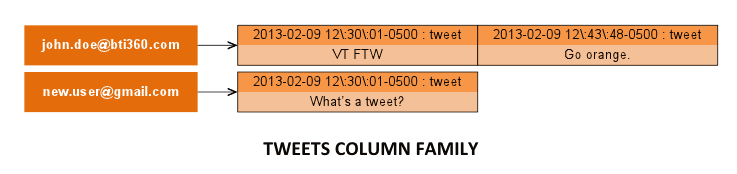
john.doe@bti360.com in fact has only one row containing tweets, unlike the two cqlsh claimed. Each tweet has its own “composite column”, containing two components in its name: the time_posted for the tweet, and the name “tweet”. C* creates composite columns by prepending the values for any extra fields in the PRIMARY KEY (e.g. time_posted) to columns for each field not used in the PRIMARY KEY statement (e.g. tweet). Composite columns allow C* to store elements with multiple layers in a single row. Let’s explore further by adding a subject column to our tweets column family with CQL, along with subjects for some tweets:
ALTER TABLE tweets ADD subject varcharUPDATE tweets SET subject = 'College' WHERE email = 'john.doe@bti360.com' AND time_posted = '2013-02-09 12:30:01-0500';UPDATE tweets SET subject = 'Thought of the day' WHERE email = 'john.doe@bti360.com' AND time_posted = '2013-02-09 12:43:48-0500';Notice that WHERE statements are constrained to only key components, not column values, a limitation of CQL vs SQL. From cassandra-cli, execute list tweets; and you should see:

Notice that tweets may or may not have subjects, and the subject and tweet columns for each tweet are grouped. C* sorts columns component by component, and storing many objects in a “wide row” like this is a common design pattern; C* supports up to two billion columns per row. It’s easy to retrieve just the columns associated with particular objects from a wide row. Cassandra’s architecture also is such that retrieving column ranges is much faster than row ranges.
That wraps up our behind the scenes tour with Cassandra for today. Next week we’ll talk more about her composites, as well as introduce her counters and collections. See you then!