Until now in our previous blogs we’ve used Cassandra (C*) with only a single node, which is practically never done. So today let’s continue our walk with Cassandra and follow the below screencast to install Cassandra Cluster Manager (ccm). Then bring up a five-node cluster.
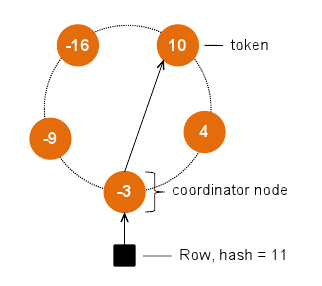
First, some background. A cluster is arranged as a ring of nodes. Clients send read/write requests to any node in the ring; that node takes on the role of coordinator node, and forwards the request to the node responsible for servicing it. A partitioner decides which nodes store which rows. The recommended partitioners assign rows to nodes based on a hash value of the row key. Nodes are assigned tokens that evenly divide the full range of possible hash values. The figure on the right, for simplicity’s sake, assumes hash values range from -16 to +16. Each node stores rows with hashes between its token and up to the next node’s token. Thus, our example row with a hash of 11 is stored in the node with token 10.
Connect cqlsh to the first node in our ring with ccm node1 cqlsh, and create a keyspace:
CREATE KEYSPACE demo WITH replication = {'class':'SimpleStrategy', 'replication_factor':3};The replication factor states how many nodes receive each row written to column families in the demo keyspace. In this case, three of our five nodes receive every row of data. A replication strategy determines which nodes hold replicas of a row. SimpleStrategy picks the next N-1 nodes clockwise around the ring from the node that stores the row. Our example row with hash -15 is stored in the node with token -16, and is replicated to nodes 10 and 4. C* provides other strategies that take into account multiple data centers, both local and geographically dispersed.
Create a table with some simple data in cqlsh:
USE demoCREATE TABLE testcf ( id int PRIMARY KEY, col1 int, col2 int );INSERT INTO testcf (id, col1, col2) VALUES (0, 0, 0);The row we just created will be replicated across three nodes totally automatically, without any effort on our part. Exit cqlsh, and check which nodes have the testcf row with key 0 with:
nodetool -p 7100 getendpoints demo testcf 0Assume nodes 127.0.0.{3,4,5} have row 0. Take two of those three nodes down, and connect to any remaining node:
ccm node3 stopccm node4 stopccm node1 cqlshUSE demo;SELECT * from testcf;Voila, our data is still accessible, even with two nodes down. Thanks to C*’s peer-to-peer architecture, where any node can act as a coordinator node, we don’t even have to connect to node 5 specifically – any node will do! Take node 5 down and reconnect to any remaining node to try the query again. This time, we get an error message stating nodes were unavailable.
Cassandra’s fault tolerance and availability provided by replication and its peer-to-peer architecture are major features. With C*, applications can approach 0% downtime, without requiring an army of expensive database administrators to do it! Adding and removing to/from a C* cluster is equally trivial – C* does nearly all the legwork behind the scenes. As they say however, there is no free lunch. In our final entry, we’ll discuss eventual consistency, necessitated by these benefits, its impact on applications, and wrap up our discussion on Cassandra’s architecture. Hope to see you there!